Die erste Anwendung des Larmonita-b2-Generators startete ich am 29.06.2009. Ich nutzte zur Realisierung eine MYSQL-Datenbank als Gedächtnisspeicher. Als binäre (oder auch duale) Werte verwendete ich eine Zufallsfolge, erzeugt über den Zeitraum vom 16.03.2009 bis zum 07.06.2009. Ich wählte die fortlaufenden erzeugten Zahlen an einem speziellen Tisch, unter Verwendung des am Tisch bereitstehenden Kessels (der innerhalb dieser Zeit ausgetauscht worden sein kann).
Die Einstellung für die Untersuchung erfolgte wie folgt: die ersten 40 Stellen werden benutzt, um den aktuellen XXwert (Schublade) zu ermitteln. Anschließend wurden die nächsten 90 Werte (also die Stellen 41-130) sowohl in die zugewiesenen Wertefächer einsortiert als auch auf den im Wertefach bestehenden aktuellen Trend untersucht. Nach einem Durchlauf an Stelle 131 angelangt, schnitt der Lb2-Generator die erste Zelle des Wertestrangs ab und führte die Berechnung von vorne durch.
(Weshalb die Anzahl der in die Wertefächer eingetragenen Ereignisse nicht unabhängig voneinander sind, insbesondere am Anfang der Prozedur. Denn die Werte ähneln sich, auch wenn keine Berechnung der anderen exakt gleicht. (Abhilfe verspräche hier nur eine Erweiterung des Wertespektrums, also statt 0-200 auf 0-10000.)
Zur Illustration einige Beispielwerte für die Abfolge der Zahlwerte aufeinander:
150 - 175 - 188 - 194 - 96 - 149 - 174 - 187 - 194 - 96 - 48 - 124 - 62 - 31 - 116 - 58 - 29 - 14 - 108 - 53 - 27 - 114 - 157 - 78 - 139 - 170 - 185 - 92 - 146 - 173 - 86 - 143 - 71 ...
Diese Werte bewegen sich im vorher definierten Rahmen oder Wertekorridor von 0 bis 200; insgesamt sind es 200 Wertefächer, weil durch den gewählten Bestimmungsparameter ((x+203)/403 und (y/403) oder vice versa) verhindert wird, dass ein Wertefach mit Ergebnis 100 erreicht kann.
Oder noch präziser: der Bonuswert 203, der zu dem aktuellen Zahlwert addiert wird vor der nächsten Zahlwertberechnung, schließt aus, dass x oder y den Wert 100 annehmen. Man müsste den Bonuswert geringer ansetzen, um auch das Ereignis 100 zu ermöglichen. Der Bonuswert bestimmt also die Laufweite, das Spektrum der Zahlwerte.
Erste Ergebnisse
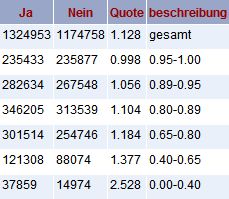
Nach etwa 30 Stunden Laufzeit des Generators hatte ich die Gesamtzahl von insgesamt 5.000.000 Einträgen in allen Wertefächern erreicht und beschloss, hier den Generator erst einmal zu stoppen. Das Resultat sah wie folgt aus:
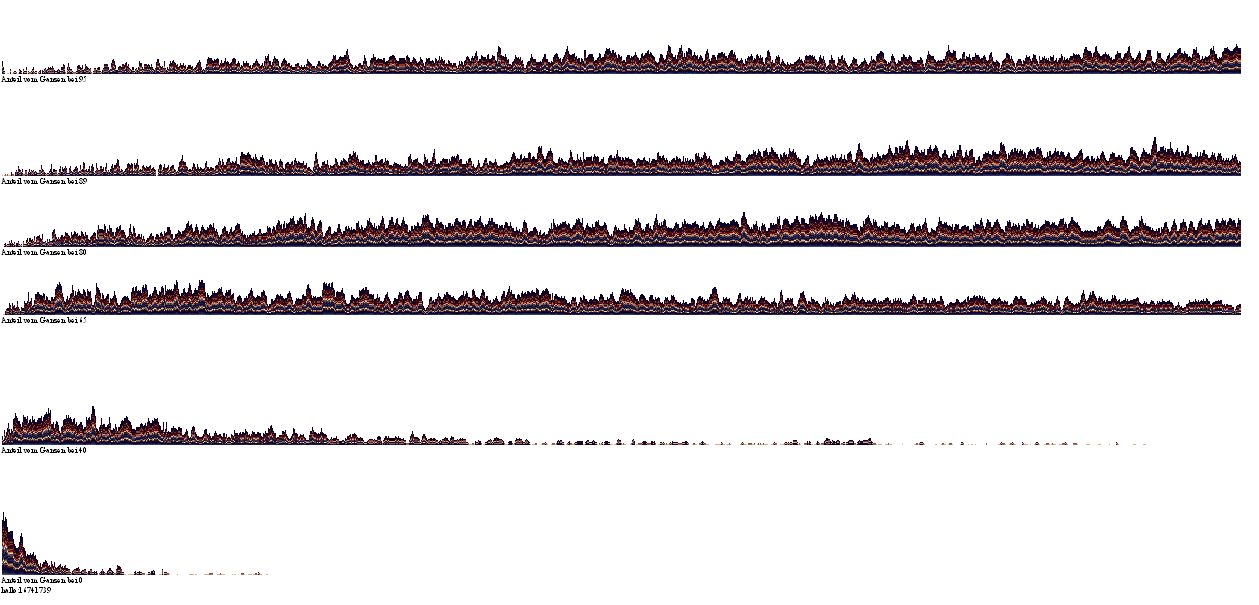
Wenn Sie mögen, klicken Sie auf das Bild, und eine Lightbox zeigt ihnen die Details ...!
Eine Erklärung dieser Abbildung wird vonnöten sein: Die oberste Zeile zeigt den Prognose- oder Ja-Nein-Quotienten: Im Idealfall müssten alle Quotienten 1.0 ergeben, also ebensoviele Ja- wie Nein-Einträge.
Ganz links steht das Wertefach 0, der weiße Leerstreifen in der Mitte ist die Leerstelle 100, der rechteste Wert steht für das Wertefach 200. An dieser Stelle möchte ich anmerken, dass die linke und die rechte Hälfte zueinander komplementär sind. Ein niedriger Ja-Nein-Quotient etwa an der Stelle 99 (gleich links von der leeren Mitte) korrespondiert mit einem höheren Ja-Nein-Quotientwert gleich rechts der Mitte. Das kommt daher, dass in jedem Messvorgang ein Wertepaar abgefragt wird und nicht nur ein Einzelwert. Wenn ich mit der ersten Prozedur den Wert 99 ermittele, dann ist dieser ermittelt für das eine Ereignis, in diesem Beispiel die Farbe Rot. Zugleich hat die andere Farbe den ergänzenden Restwert, also 200-99 = 101. Beide Werte summieren sich qua definitionem immer auf 200, und ihr Quotient ist demnach automatisch q und 1/q.
(Genau genommen benötigte man überhaupt nur eine der beiden Hälften.)
Erste Deutung: Bei insgesamt 5.000.000 Einträgen kommen auf jedes Wertfach durchschnittlich 25.000 Werte, weshalb ein Verhältnis von 22.545/16.588 oder 36% wie beim Wertepaar 83|117 eine doch hoch erscheinende Abweichung darstellen.
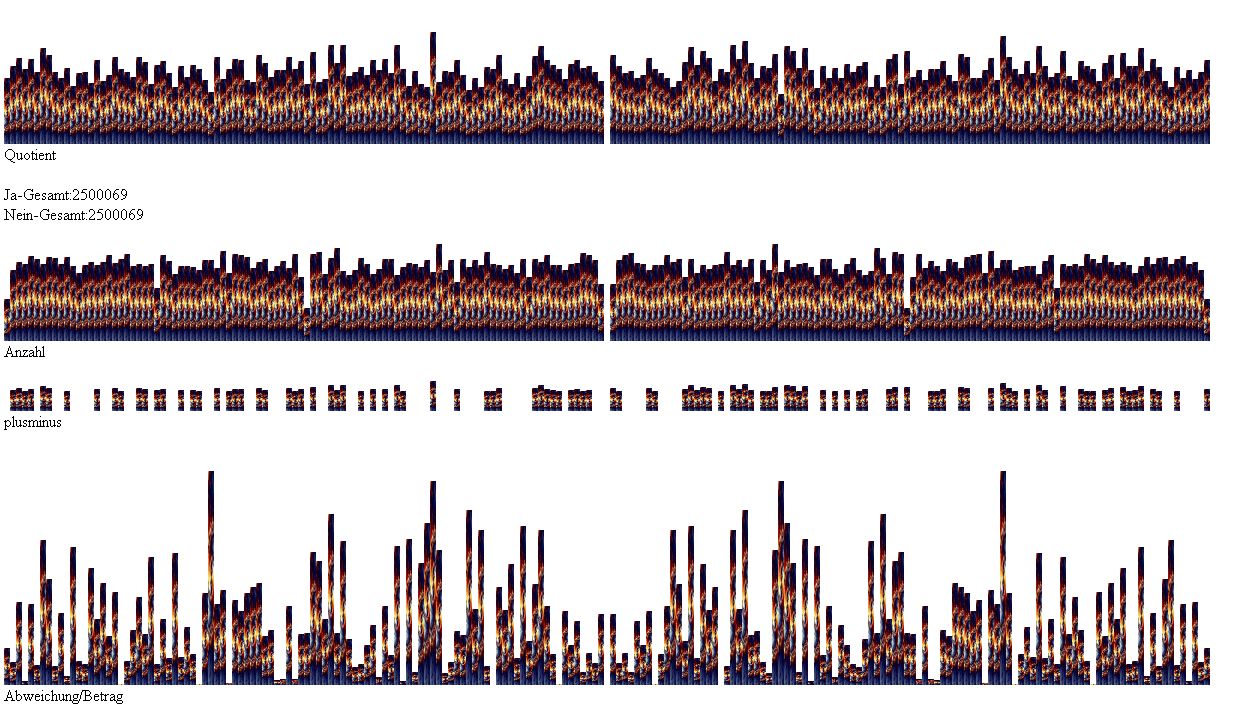
Die zweite Zeile zeigt die Wertefächer von 0-200, gemessen an der kumulativen Verteilung. Diese Statistik sieht ausgezackt aus, doch welche Erwartungswerte hier angemessen wären, ist zum jetzigen Stand nur zu erahnen. Dass an Stellen wie 26/51/76 bzw. 124/149/174 die Anzahl gering ist, mag aber mit der nicht möglichen Wertezahl 100 in Zusammenhang stehen.
Mit welchem Bonuswert sich die gleichmäßigste Verteilung herstellen ließe, müssen weitere Experimente erweisen. Möglich, dass bei einem Spektrum von 0-200 auch der Bonuswert 200 die beste Näherung leisten kann.
In der dritten Zeile der obigen Lightbox werden die Quotienten in den Wertefächern noch einmal als Plusminus-Diagramm dargestellt. Ist der Quotient größer als 1, wird er - seiner Höhe entsprechend - illustriert, ist er geringer, bleibt eine weiße Leerstelle. Was nun wäre zu erwarten, wenn hier purer Zufall walten würde? Jedes Fach würde nur zufällig größer 1 sein oder kleiner, weshalb eine Gruppierung von beispielsweise vier Wertefächern mit Werten über 1 der Wahrscheinlichkeit 1:16 entspräche. Das heißt: Trauben von nebeneinanderliegenden Quotienten größer 1 oder kleiner 1 sind möglich, aber mit zunehmender Länge unwahrscheinlich.
Im obigen Fall tritt 21x das Ereignis 1 einzelner Wert auf, 15x 2 Werte nebeneinander, 8x 3 Werte, 5x 4 Werte, 2x 5 Werte.
Zu erwarten wären im Idealfall annähernd folgende Zahlen: 26 - 13 - 6,5 - 3,2 - 1,6. Was insgesamt noch tolerabel wäre angesichts der geringen Wertemenge, aber aufmerken lassen die Ballungen von hohen Quotienten an mehreren Stellen.
In der vierten und untersten Zeile wird das Verhältnis der Abweichung des Quotienten von der Anzahl dargestellt. Und obwohl die Anzahl weitestgehend konstant ist zwischen den Wertefächern 0-200, meint man nahe der 100 zur rechten und linken einen verkleinerten Abweichungs-Anzahls-Quotienten zu erkennen.
Special Features
Die bisherigen Ergebnisse sind noch nicht spektakulär, eigentlich einer Publikation nicht wert. Spannender wird es, wenn man nun einen zweiten Quotienten misst: Ich habe eine weitere Datenbank angelegt, in der ich nach tausend neuen Eintragungen in den Wertefächern (als Gesamtsumme) berechnete, wie gut die Prognosequote lag. Also: die Tendenzen innerhalb der Wertefächer würden sich auch insgesamt wiederspiegeln. Diese Verlaufskurve der Prognosen in 1000er-Schritten ist die oberste in der zweiten Abbildung:
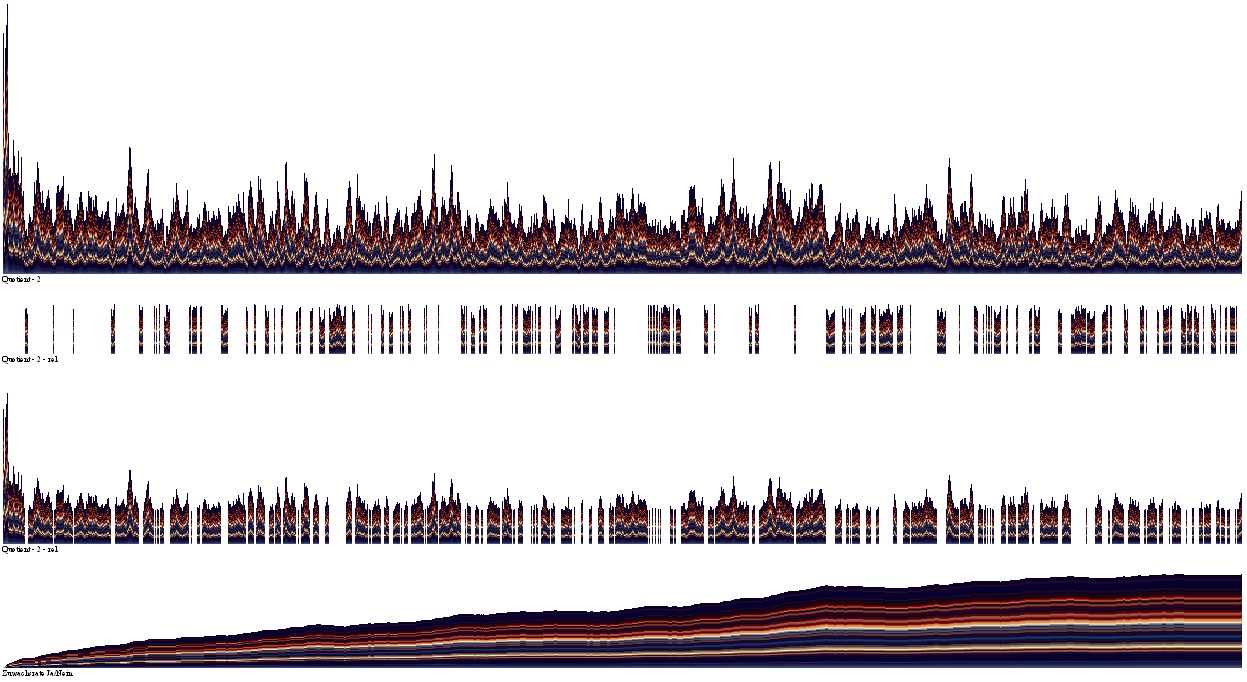
Also: Links ist der Beginn, die Werte sind anfangs erwartungsgemäß enorm hoch, weil sich in den noch mit wenig Werten gefüllten Wertefächern schnell Tendenzen abzeichnen, die durch Überlagerungen zustandekommen. Doch nach einigen tausend Berechnungen bildet sich dieser Vorteil zurück.
Besonders interessant sind nun die beiden daruntergeordneten Zeilen: die obige zeigt (wie die Plusminus-Abbildung oben) die unter 1.00 liegenden Quotienten-Werte, also schlechte 1000er-Prognosen. In der Zeile darunter sind die 1000er-Prognosen abgebildet, die über dem Wert 1.00 liegen. Wie man nun unschwer erkennen kann, ist konstant von Links=Anfang bis Rechts=Ende ein Überwiegen der positiven Prognose zu beobachten. Oder, mit anderen Worten: Larmonita hat sich wirklich etwas gemerkt! Und auch wenn es mitunter längere Durststrecken gibt, auf lange Sicht gewinnt das Gedächtnis immer!
Die unterste Zeile zeigt den Gewinn an: der Wert steigt im Laufe der Zeit nahezu konstant an, von zeitweise auftretenden Verflachungen einmal abgesehen. Ein purer Zufall hingegen dürfte hier gar nichts anzeigen, der Gewinn wäre gleich null.